TL;DR: 3D HAMSTER predicts metrically grounded 3D end-effector
trajectories from a depth-augmented VLM and executes them through a pointcloud-based low-level
policy, enabling robust manipulation across diverse real-world scenes, instructions, and visual
conditions.
Approach
Method
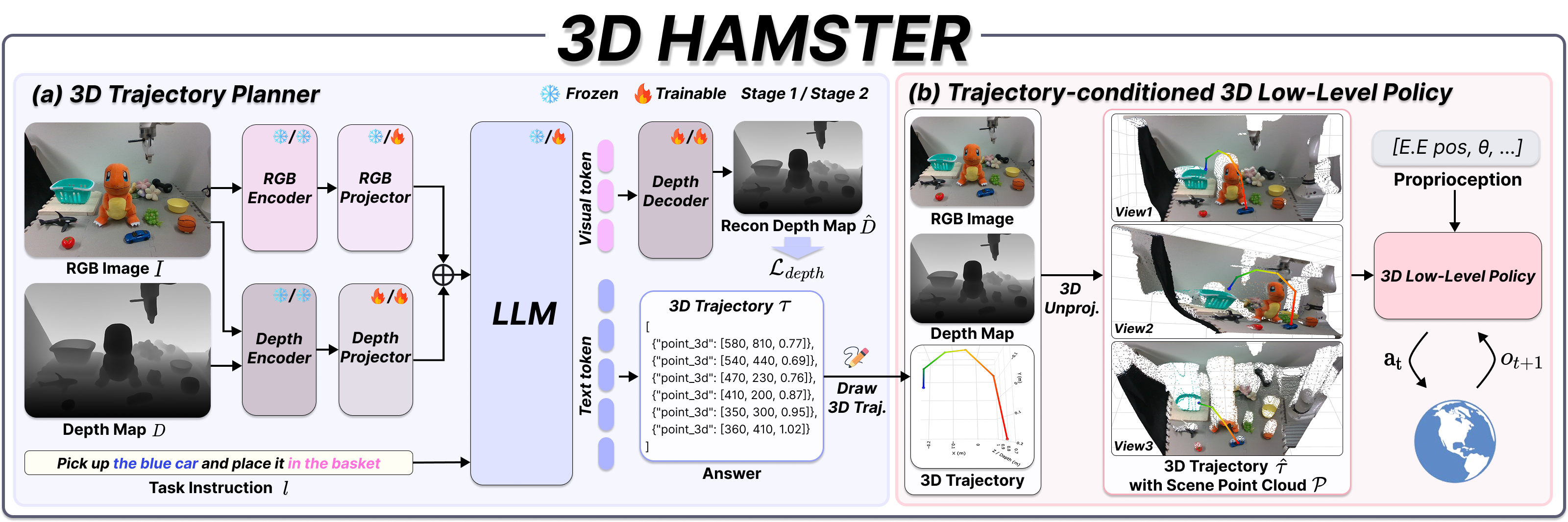
Hierarchical Vision-Language-Action (VLA) models split manipulation into a high-level planner and a low-level policy. Today's strongest low-level policies operate on 3D point clouds, yet existing planners predict only 2D pixel trajectories — forcing each waypoint to inherit the depth of whatever surface lies beneath it.
3D HAMSTER removes that mismatch. We build:
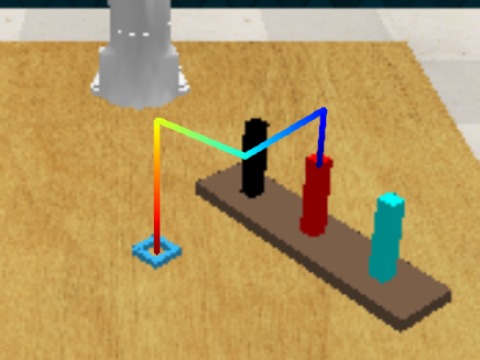
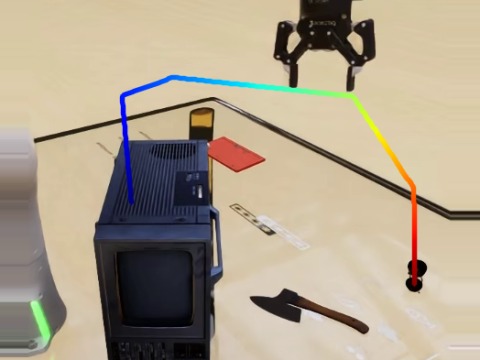
- A depth-aware VLM planner — augmented with a geometry encoder and a dense depth-reconstruction objective — that predicts metric 3D end-effector trajectories. Visualized in §02.
- A 3D-trajectory-conditioned point-cloud policy (rectified-flow, 3DFA) trained to roll out the planner's predictions on real hardware. Real-world rollouts in §03.
Key Contributions
- 3D-native hierarchical VLA. The VLM planner outputs metric 3D end-effector trajectories that feed directly into a point-cloud low-level policy — no 2D-to-3D translation in between.
- Recipe for metric-3D VLM prediction. A depth encoder, a depth-reconstruction objective, and a curated data mixture turn Qwen3-VL into a planner whose (u, v, d) waypoints unproject to consistent world coordinates.
- Geometry-grounded generalization. Planning in metric 3D — instead of pixel paths whose depth must be inferred at execution — yields manipulation that holds across novel scenes, instructions, and lighting.